Results
Grounding Ability
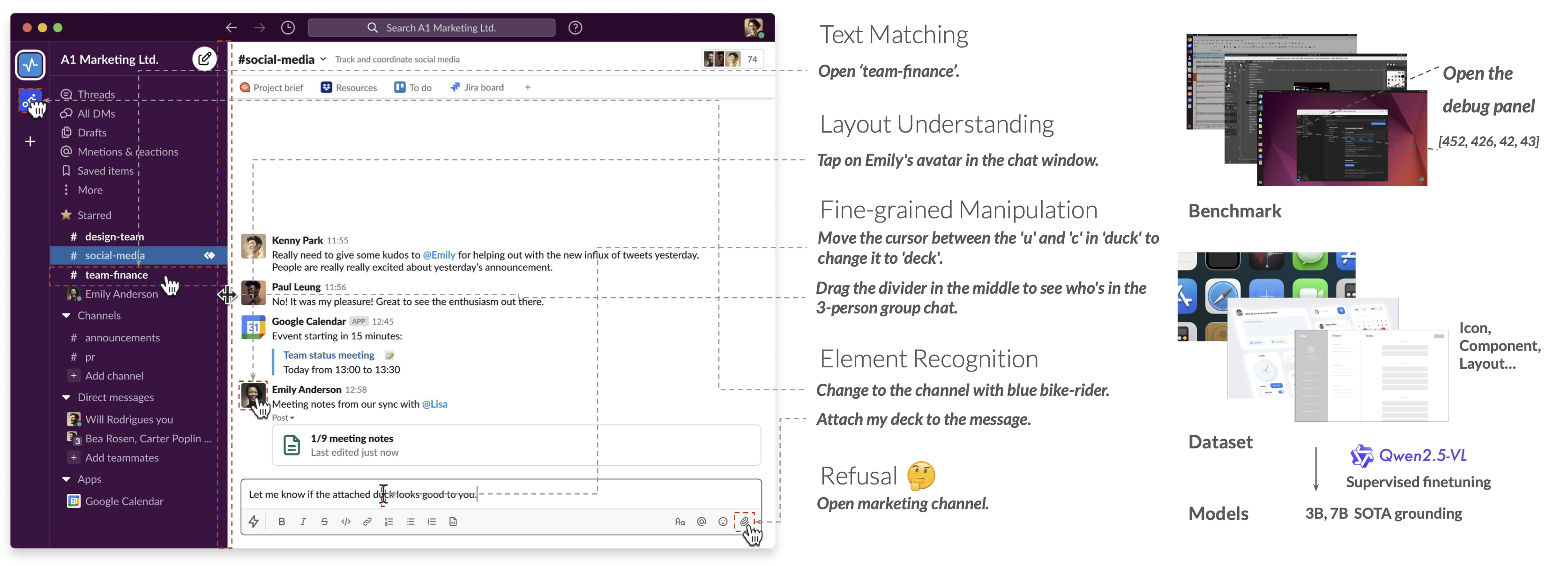
We select several benchmarks for GUI grounding. The most commonly used benchmarks in the past include ScreenSpot-v2, ScreenSpot-Pro, which focuses on high-resolution and professional software charts, and OSWorld-G, which we use to evaluate model performance on fine-grained and functional components.
| Model | ScreenSpot-v2 | ScreenSpot-Pro | OSWorld-G |
|---|---|---|---|
| UI-TARS-7B | 91.6 | 35.7 | 47.5 |
| Operator | 70.5 | 36.6 | 40.6 |
| Qwen2.5-VL-3B | 80.9 | 25.9 | 27.3 |
| Qwen2.5-VL-7B | 88.8 | 27.6 | 31.4 |
| Jedi-3B | 88.6 | 36.1 | 50.9 |
| Jedi-7B | 91.7 | 39.5 | 54.1 |
Agentic Ability
We evaluate our approach on two computer use benchmarks in online environments: OSWorld and WindowsAgentArena. We employ: (1) GPT-4o as the high-level planner that processes user instructions, and (2) Jedi as the grounding model that converts the planner's low-level instructions into executable actions.
| Model | OS SR | WAA SR |
|---|---|---|
| GPT-4o (15 steps) | 5.0 | 9.4 |
| UI-TARS-72B (50 steps) | 22.7 | - |
| Operator (15 steps) | 19.7 | - |
| Operator (50 steps) | 32.6 | - |
| Claude 3.7 Sonnet (50 steps) | 26.0 | - |
| Aguvis-72B w/ GPT-4o (15 steps) | 17.0 | - |
| Jedi-3B w/ GPT-4o (15 steps)^ | 22.4 ±0.33 | 29.1 ±0.57 |
| Jedi-7B w/ GPT-4o (100 steps)^ | 27.0 ±1.81 | 33.7 ±0.82 |
| Jedi-7B w/ o3 (100 steps)^ | 50.2 ±0.83 | - |
^Agentic results for Jedi are the average of four runs. More detailed results are available in the paper.
The figure below illustrates the performance of Jedi-7B w/ o3 on OSWorld, where the maximum number of steps is set to 100. We present how performance varies with the number of steps for both Pass@4 and Avg@4 metrics.